







Q-Learning سریع اکتشافی توزیع شدهیکشنبه 12, نوامبر 2017
این مقاله سعی کرده q-learning را بهینه کند که بصورت کامل برای شما ترجمه شده و در زیر میتوانید ترجمه آن را مشاهده کنید.همچنین در انتهای ترجمه بصورت خلاصه و برای دوستانی که می خواهند آن را ارائه دهند فایل پاورپوینت آن نیز قرار داده شده است که این فایل توسط تیم همیارپروژه ایجاد شده است:
Q-Learning سریع اکتشافی توزیع شده[۱] برای مدیریت قوی طیف شناختی در سیستم های سلولی LTE
چکیده
در این مقاله الگوریتمی برای دسترسی به طیف پویا (DSA) در سیستم های سلولی LTE – ICIC توزیع شده تسریع کننده (DIAQ) Q-learning پیشنهاد شده است. این ترکیبی از سیگنالینگ یادگیری تقویتی توزیع شده (RL) و هماهنگی تداخل بین سلولی استاندارد (ICIC) در لینک پایین رونده LTE با استفاده از یادگیری تقویتی سریع اکتشافی (HARL) می باشد. علاوه بر این، ما یک رویکرد جدید مبتنی بر شبکه بیزین برای تجزیه و تحلیل نظری DSA مبتنی بر RL ارائه می دهیم. این، بهبود پیش بینی شده ای را در رفتار همگرای به دست آمده توسط DIAQ، در مقایسه با RL کلاسیک توضیح می دهد. این طرح همچنین با استفاده از شبیه سازی هایی در مقیاس بزرگ یک شبکه رویداد موقت استادیوم ارزیابی می شود. در مقایسه با یک رویکرد ICIC اکتشافی معمولی ، DIAQ کیفیت خدمات را به طور قابل توجهی بهبود می بخشد و از تراکم بارگذاری شبکه به میزان قابل توجهی پشتیبانی می کند. علاوه بر این، DIAQ به طور چشمگیری عملکرد اولیه را بهبود می بخشد، سرعت همگرایی را افزایش می دهد و بهبود عملکرد حالت پایدار الگوریتم Q-learning توزیع شده ی پیشرفته، پیش بینی های نظری را تایید می کند. در نهایت، طرح ما مطابق با استانداردهای LTE فعلی طراحی شده است. بنابراین، اجرای آسان دستگاه توزیع شده هوشمند را برای سازماندهی کامل خود در شبکه های تجاری موجود ممکن می سازد.
کلمات کلیدی – Q-Learning سریع اکتشافی ، دسترسی به طیف پویا، هماهنگی تداخل بین سلولی.
۱٫مقدمه
یکی از وظایف اساسی یک سیستم سلولی ،مدیریت طیف[۲] ، با تقسیم بندی طیف موجود به مجموعه ای از بلوک های منابع مرتبط ، و اختصاص آنها به تماس های صوتی و انتقال داده ها است به گونه ای که کیفیت خدمات (QoS) خوب را برای کاربران فراهم کند. تکنیک های دسترسی به طیف پویای انعطاف پذیر (DSA) نقش کلیدی در استفاده از طیف داده بازی می کند. به عنوان مثال، یکی از الزامات کلیدی برای سیستم LTE یک فاکتور استفاده مجدد از ۱است [۱]. بنابراین، نیازهای ذاتی برای تکنیک های DSA در چنین سیستم هایی برای کاهش اثرات دخالت های سلولی بر روی عملکرد سیستم و QoS ارائه شده به مشترکین تلفن همراه وجود دارد. برای رسیدن به این هدف، سیستم های LTE از یک رابط اختصاصی X2 برای تبادل اطلاعات مربوط به تداخل در بین eNodeB های همسایه (eNDEs)استفاده می کنند [۲]. این فرایند به عنوان هماهنگی تداخل بین سلولی (ICIC) نامیده می شود.
یک روش جدید در حال پیشرفت برای DSA ی هوشمند، یادگیری تقویتی (RL) است ؛ یک روش یادگیری ماشین ، با هدف ایجاد راه حل هایی برای مشکلات تصمیم گیری می باشد که تنها از طریق آزمایش و خطا انجام می شود [۳]. این به طور موفقیت آمیز در محدوده مشکلات و سناریوهای DSA مورد استفاده قرار گرفته است مانند شبکه های رادیو شناختی [۴]، شبکه های femtocell [۵]، شبکه های مش بی سیم شناختی [۶]، و همچنین شبکه های سلولی عمومی [۷] . الگوریتمRL ی که به طور گسترده در هر دو زمینه هوش مصنوعی و ارتباطات بی سیم استفاده می شود، Q-learning است [۸]. بنابراین، بیشتر ادبیات روی DSA مبتنی بر RL در Q-learning و تغییرات آن تمرکز دارد، به عنوان مثال، [۶] [۷] [۹]. در این مقاله، DSA مبتنی بر Q-learning توزیع شده است. روش Q-learning توزیع شده مزایایی بیشتر از روش های متمرکز دارد در آن هیچ سربار ارتباطی برای رسیدن به هدف یادگیری لازم نیست و عملیات شبکه به یک واحد محاسباتی تکیه نمی کند. همچنین، در صورت لزوم، امکان ورود و حذف ایستگاه های پایه از شبکه را آسان تر می کند. به عنوان مثال، چنین پروتکل های فرصت طلب توزیع شده ای به خوبی به شبکه های رویداد موقت و سناریوهای امداد رسانی کمک می کند، جایی که معماری های شبکه قابل ارتقاء با توپولوژی های غیر برنامه ریزی شده یا متغییر، ممکن است برای تکمیل هر زیرساخت بی سیم مورد نیاز باشد.[۱۰]
اگر چه الگوریتم های RL مانند Q-learning نشان دهنده یک رویکرد قدرتمند برای حل مسئله هستند، اشکال مشترک آنها این است که نیاز به تکرارهای یادگیری بسیاری است تا به یک راه حل قابل قبول همگرا شود. یکی از جدیدترین راه حل های امیدوار کننده برای این موضوع، که در زمینه هوش مصنوعی پیشنهاد شده است، یک روش یادگیری تقویتی سریع اکتشافی (HARL) است. هدف آن افزایش سرعت الگوریتم RL، به ویژه در دامنه چند عاملی با هدایت روند اکتشاف با استفاده از اطلاعات اضافی اکتشافی است . [۱۱] در [۱۲] ، استدلال مبتنی بر مورد برای افزایش سرعت اکتشاف در یک الگوریتم RL چند عاملی برای ارزیابی شباهت بین حالتهای محیط و ایجاد یک حدس در مورد اینکه چه اقداماتی باید در یک حالت مشخص انجام شود، بر اساس تجربه ای که در سایر حالت های مشابه به دست آمده ،استفاده می شود. در [۱۱]، Bianchi و همکاران همگرایی چهار الگوریتم HARL چند عامله را ثابت می کنند. و نشان می دهند که چگونه از الگوریتم های RL معمولی بهتر عمل می کنند.در ادبیات شواهدی وجود ندارد که از روش HARL در دامنه ارتباطات بی سیم استفاده شده باشد.
هدف از این مقاله، حل مسئله عملکرد ضعیف زمانبندی الگوریتم DSA مبتنی بر RL ، با پیشنهاد یک طرح DSA شناختی است، که ترکیبی از Q-learning توزیع شده و ICIC با استفاده از یک سازگاری جدید از چارچوب HARL است. علاوه بر این، مطابق با استانداردهای LTE فعلی طراحی شده است و توانایی دستگاه توزیع شده هوشمند را به راحتی در LTE فعلی یا آینده اجرا (پیاده سازی)می کند.
در کار قبلی در مورد ترکیب ICIC و RL، محققان فقط استفاده از RL را برای یادگیری پارامترهای مختلف مربوط به ICIC یا مدیریت منابع رادیویی در سیستم های سلولی OFDMA مانند LTE یا WiMAX در نظر گرفتند. به عنوان مثال، Simsek و همکارانش [۱۳]از RL برای یادگیری بهینه محدوده باباس سلول و استراتژی های تخصیص توان و مقایسه آنها با روش های ICIC استاتیک استفاده کردند؛ Dirani و Altman [14] از یک الگوریتم Q-learning فازی و ICIC برای یادگیری استراتژی تخصیص توان هماهنگ استفاده می کنند؛ و Vlacheas و همکاران [۱۵] از یک اصل RL فازی برای تنظیم اتوماتیک شاخص انتقال توان باند باریک نسبی (RNTP) استفاده کردند که یک پارامتر ICIC کلیدی در لینک پایین رونده LTE است. با این حال، هیچ شواهدی از کار قبلی در ادبیات، در مورد استفاده از روش های اکتشافی ICIC برای افزایش عملکرد الگوریتم DSA مبتنی بر RL وجود ندارد.
بقیه مقاله به شرح زیر سازماندهی می شود: بخش ۲ ویژگی های فعلی سیگنالینگ ICIC را در لینک پایین رونده LTE توضیح می دهد. بخش ۳ رویکرد Q-learning توزیع شده را برای DSA توصیف می کند. در بخش ۴ فرمول بندی چارچوب HARL را معرفی می کنیم و طرح DIAQ برای DSA در سیستم های سلولی LTE پیشنهاد شده است . در بخش ۵ ما یک روش جدید مبتنی بر شبکه Bayesian را برای تحلیل نظری و ارزیابی طرح پیشنهادی استفاده می کنیم. بخش ۶ عملکرد آن را با شبیه سازی یک سیستم سلولی در مقیاس بزرگ ارزیابی می کنیم. نتایج در بخش ۷ ارائه شده است.
- هماهنگی تداخل درون سلولی در لینک پایین رونده LTE
عامل محدود کننده اصلی برای عملکرد توان عملیاتی شبکه در سیستم های LTE، تداخل بین سلولی است،چرا که نیاز کلیدی برای سیستم های LTE یک عامل استفاده مجدد از ۱ است [۱] ، یعنی اتحاد کامل طیف برای هر (eNB) eNodeB در شبکه ی در دسترس است. همین در مورد دیگر سیستم های تلفن همراه آینده که تکنیک های پیشرفته DSA را به کار می برند استفاده می شود،همانطور که مخالف روش های تخصیص منابع استاتیک است [۱۶].در نتیجه ، تکنولوژی مدیریت تداخل کلیدی در زمینه LTE، هماهنگی تداخل بین سلولی (ICIC) است. هدف ICIC کاهش تداخل بین سلول های مجاور با تبادل اطلاعات بین eNB های همسایه در رابط X2 است[۱]. این تبادل سیگنال ICIC در شکل ۱ با استفاده از یک معماری شبکه سلولی شش ضلعی کلی نشان داده شده است. در اینجا، eNB مرکزی یک سیگنال ICIC را به eNB های اطراف آن می فرستد تا به آنها اطلاع دهد که در آن بخش های طیف احتمال دارد که با آنها مواجه شود.
فرمت پیام های تبادل شده بین eNBs با استفاده از ICIC درلینک پایین رونده LTE توسط GPP 3استاندارد شده و به عنوان شاخص انتقال توان باند باریک نسبی(RNTP) [۱۷] اشاره می شود. این شامل یک نگاشت بیتی است که نشان می دهد که کدام منبع یک eNB در حال برنامه ریزی را برای انتقال با توان بالا با تنظیم بیت های مربوطه به ۱ مسدود می کند. آستانه ، برای تصمیم گیری مورد استفاده قرار می گیرد اگر توان انتقال بالا یا پایین باشد با استفاده از آستانه RNTP بدست می آید که می تواند مجموعه ای از مقادیر استاندارد شده زیر را در بر گیرد:
این در نسبت dB برای متوسط توان انتقال در یک سلول داده شده اندازه گیری شده است.
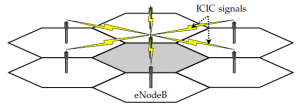
شکل ۱٫ سیگنالینگ ICIC در میان eNodeB های مجاور
۳ . دسترسی طیفی دینامیک (پویا) مبتنی بر Q-learningتوزیع شده
در DSA مبتنی بر یادگیری تقویتی توزیع شده (RL) خالص وظیفه هر eNB یادگیری در میان زیر کانال های موجود تنها از طریق آموزش و خطا، بدون تکرار پیچیده و بدون تبادل اطلاعات با دیگر eNB ها است ، مثلا [۷]. به این ترتیب ،تکرار متناوب الگوها به صورت خودکار با استفاده از هوش مصنوعی توزیع شده بدون نیاز به دانش پیشین در یک محیط معین، ظاهر می شوند.
۳٫۱ یادگیری تقویتی
RL نوعی از مدل یادگیری ماشین است که هدف آن یادگیری شرایط مطلوب استفاده از هر اقدام قابل دسترس در هر حالت از محیط، تنها از طریق آزمایش و خطا است [۳]. شرایط مطلوب یک عمل توسط یک مقدار عددی شناخته شده به صورت Q-value – پاداش تجمعی مورد انتظار برای انجام یک اقدام خاص در یک حالت خاص، نشان داده شده است ، همانطور که در معادله زیر نشان داده شده است:
که Q(s, a) ، مقدار Q برای عمل a در حالت s است ، rt پاداش عددی دریافت شده در مرحله زمانی t می باشد که پس از عمل a در حالت s قرار می گیرد، T تعداد کل مراحل زمانی تا پایان فرایند یادگیری یا حالت فرعی است، و یک عامل کاهش است .
کار یک الگوریتم RL برای برآورد Q(s, a) برای هر عمل در هر حالتی و سپس ذخیره در یک آرایه شناخته شده به عنوان جدول Q می باشد .در برخی موارد که در آن محیط نمی تواند توسط حالت ها ارائه شود، تنها فضای عمل و Q-table 1 بعدی Q(a) می تواند در نظر گرفته شود [۱۸]. کار الگوریتم RL سپس ساده تر می شود؛ هدف آن برآورد مقدار مورد انتظار تنها یک پاداش برای هر عمل در دسترس برای عامل یادگیری است:
این نیز برای DSA مبتنی بر Q-learning در سیستم های سلولی قابل اجراست ، مانند[۷] [۱۹] [۲۰] .
۳٫۲ Q-learning توزیع شده ی بیطرف
یکی از رایجترین الگوریتم های RL مورد استفاده Q-learning است [۸]. به طور خاص، یک نوع بی قاعده ساده این الگوریتم، همانطور که در [۱۸] فرموله شده است، نشان می دهد که برای چندین مشکل یادگیری توزیع شده DSA موثر است، مثلا [۷] [۱۹] [۲۰].
هر eNB یک جدول-Q Q(a) را حفظ می کند به طوری که هر زیر کانال a دارای Q-Value مرتبط با آن است. به محض ورود هر فایل ، eNB یا یک زیر کانال را برای انتقال آن اختصاص داده یا آن را اگر تمام زیر کانال ها اشغال شده باشند بلوکه می کند. این تصمیم می گیرد که کدام زیر کانال براساس جدول Q فعلی و استراتژی انتخاب عمل حریصانه توسط معادله زیر تعیین شود:
که زیر کانال انتخاب شده برای تخصیص است ، و Q(a) مقدار-Q زیر کانال a است . مقادیر Q-tables با صفر مقدار دهی اولیه می شوند بنابراین تمام eNB ها با انتخاب یکسان از میان تمام زیر کانالهای موجود شروع به یادگیری می کنند. یک Q-table توسط یک eNB هر بار که آن تلاش می کند یک زیر کانال را یرای یک انتقال فایل به صورت یک تقویت مثبت یا منفی اختصاص دهد به روز می شود. معادله به روز رسانی بازگشتی برای آموزش Q-learning بی طرف، همانطور که در [۱۸] تعریف شده ، در زیر آمده است:
که Q (a) نشان دهنده Q-value از زیر کانال a است، r پاداش مربوط به جدیدترین محاکمه است و توسط یک تابع پاداش تعیین می شود ، و پارامتر سرعت یادگیری است که تجربیات اخیر را با توجه به برآوردهای قبلی Q-values می سنجد.
تابع پاداش، که عموما برای طیف گسترده ای از مشکلات RL قابل اجرا است و با موفقیت برای مسائل DSA در گذشته مورد استفاده قرار گرفته است [۴] [۷]، دو مقدار را باز می گرداند:
- r = -1 (تقویت منفی) ، اگر انتقال فایل به علت SINR ناکافی در زیر کانال انتخابی شکست خورده باشد.
- r = 1 (تقویت مثبت) ، اگر فایل با موفقیت ارسال شود، یعنی SINR زیر آستانه انتقال قرار نگیرد.
انتخاب مقادیر یادگیری برای این نوع ازمسائل DSA مبتنی بر Q-learning توزیع شده به طور کامل در [۷] مورد بررسی قرار گرفته است . بهترین عملکرد با استفاده از اصل Win-or-Learn-Fast (WoLF) [21] که توسط (۶) ارائه شده است، به دست می آید، که یک مقدار کمتر برای α برای آزمایش های موفقیت آمیز استفاده می شود (هنگامی که r = 1) ،و یک مقدار بزرگ برای α برای آزمایشات شکست خورده استفاده می شود (r = -1). به این ترتیب، عوامل یادگیری زمانیکه که “شکست می خورند ” سریع تر و زمان “برنده شدن” آهسته تر یاد می گیرند.
۴٫۱ Q-Learning سریع اکتشافی توزیع شده
یک مشکل رایج الگوریتم های یادگیری ماشین، مانند Q-learning توزیع شده که در بخش قبلی توصیف شد، این است که آنها معمولا برای یادگیری راه حل ها تنها از روش آزمایش و خطا بدون اطلاع قبلی از مشکل در دست استفاده می کنند. در نتیجه، انها تعداد زیادی آزمایش برای یادگیری راه حل های قابل قبول انجام می دهند. این در برنامه های در حال اجرا[۳] مانند DSA در سیستم های سلولی نامطلوب است. یک تکنیک در حال ظهور برای مقابله با این مشکل عملکرد اولیه نا چیز روش یادگیری تقویتی اکتشافی سریع (HARL)است ، که از اطلاعات اضافی اکتشافی برای هدایت روند اکتشاف استفاده می شود [۱۱].
۴٫۱ یادگیری تقویتی اکتشافی سریع
عنصر کلیدی اضافی که توسط HARL در مقایسه با RL کلاسیک ارائه شده است، یک تابع اکتشاف استنتاجی است. با توجه به [۱۱]، یک تابع اکتشافی از دانش اضافی خارجی، یا داخلی استخراج شده است که در فرایند یادگیری گنجانده نشده است. به طور کلی، هدف تابع اکتشافی برای تحت تأثیر قرار دادن انتخاب اقدام عامل یادگیری است، یعنی برای تغییر سیاست فعلی خود به طریقی که فرایند یادگیری را تسریع کند. فرمت و ابعاد باید با جدول Q که توسط عامل یادگیری داده شده استفاده می شود، سازگار باشد، به طوری که سیاست ترکیبی جدید آن می تواند با استفاده از معادله زیر استخراج شود:
که سیاست ترکیبی عامل یادگیری داده شده برای حالت ها در زمان t بر اساس جدول Q- ، و تابع اکتشافی است. اگر همیشه صفر باشد، الگوریتم به یک الگوریتم منظم (متعادل) Q-learning با یک استراتژی انتخاب حریصانه تبدیل می شود. در مورد الگوریتم Q-learning بیطرف که در بخش ۳ شرح داده شده است، تابع اکتشافی یک بعد حالت ندارد و می تواند توسط نشان داده شود.
۴٫۲ Distributed ICIC Accelerated Q-Learning
در این بخش ، ما طرح ICIC توزیع شده تسریع کننده Q-learning (DIAQ) را پیشنهاد می کنیم که ترکیب Q-learning و ICIC را با استفاده از چارچوب HARL برای کاهش ویژگی های عملکرد ضعیف زمانبندی الگوریتم های DSA مبتنی بر Q-learning انجام می دهد.
همانطور که در بخش ۲ توضیح داده شد ، با استفاده از سیگنالینگ ICIC روی رابط X2 هر eNB توانایی دانستن را دارد که بلوک های منابع مجازی( VRB ها) eNBهای همسایه به احتمال زیاد در آن دخالت می کنند، به عنوان مثال انتقال با قدرت بالای آستانه RNTP . در یک سناریو، که در آن یک کانال LTE 20 مگاهرتز که شامل ۱۰۰ VRB است به شبکه اختصاص داده می شود طول پیام RNTP 100بیت یا ۲۵ کاراکتر هگزادسیمال است. هر زیر کانال ، یعنی حداقل نهاد اختصاص داده شده به یک انتقال فایل، شامل ۴ VRB مجاور است،اگر تخصیص منبع “نوع ۰” مورد استفاده قرار گیرد [۱۷] .در مورد eNB مرکزی در شکل ۱،آن ۶ پیام RNTP از همسایگان خود دریافت می کند، هر کدام شامل ۲۵ کاراکتر هگزادسیمال می باشد که حاوی زیر کانال هایی هستند که نیاز به رزرو دارند تا از دخالت بین سلولی جلوگیری شود. ۰xF نشان می دهد که یک زیر کانال در حال استفاده توسط همسایه eNB است، ۰x0 به این معنی است که استفاده از ان توسط eNBکه پیام RNTP را دریافت می کند، امن است.
ما استفاده از این پیام های RNTP را برای ایجاد ماسک های بیتی ICIC نشان داده شده پیشنهاد می کنیم که زیر کانالها برای استفاده از هر ENB داده شده ایمن نیستند، همانطور که توسط همسایگان خود آگاه می شوند و از این ماسک های بیتی برای ایجاد توابع اکتشافی H (a) استفاده می شود، که به نوبه خود بر انتخاب واگذاری طیف ساخته شده توسط الگوریتم DSA مبتنی بر Q-learning تأثیر می گذارد.
هنگامی که یک درخواست برای انتقال فایل جدید دریافت می شود، eNB با جمع آوری آخرین پیام های RNTP از همسایگان خود در یک ماسک بیتی ICIC با استفاده از عملیات بیتی OR شروع می شود همانطور که توسط معادله زیر شرح داده می شود:
جایی که ماسک یک رشته کاراکتر ۲۵ هگزادسیمالی است نشان دهنده زیر کانال هایی است که توسط هر یک از ایستگاه های پایه مجاور توسط F ذخیره شده اند و زیر کانال های “safe-touse” توسط ۰ نشان داده می شود ، RNTPn یک کاراکتر ۲۵ هگزادسیمالی پیام RNTP از nامین همسایه eNB است و N تعداد کل eNB های همسایه است. تبادل پیام RNTP می تواند مکررا هر ۲۰ میلی ثانیه انجام شود[۱]، و مجبور نیستند هماهنگ شوند. هر eNB همیشه از آخرین پیام RNTP دریافت شده از یک همسایه معین استفاده می کند.
پس از ایجاد ماسک ICIC، ما eNB ناشی از یک تابع اکتشافی H (a) را به صورت زیر بدست می آوریم:
جایی که H(a) مقدار تابع اکتشاف برای زیر کانال a است و h یک مقدار منفی ثابت با نوسان بیشتر از محدوده کامل مقادیر ممکن Q(a) است. در مورد الگوریتم Q-learning توزیع شده که در بخش ۳ توضیح داده شده ، است، بنابراین h <-2 می باشد. H (a) می تواند برای ایجاد Q-table موقت ماسک شده Qm (a) با استفاده از معادله زیر به کار گرفته شود:
Qm(a) سپس برای تصمیم گیری مبتنی بر اکتشاف استفاده می شود، در حالی که یک فرآیند یادگیری طبیعی با استفاده از Q (a) صورت می گیرد، همانطور که در (۵) تعریف شده است.
با استفاده از Qm (a) و H(a) پیشنهادی ، eNB تضمین می کند که زیر کانال هایی که قبل از زیر کانال های “unsafe” توسط “ماسک” به عنوان “امن” مشخص شده اند، مقادیر Q را از دومی به پایین جدول Q تغییر می دهند. در حالی که همچنان ترتیب مربوطه را از لحاظ مقادیر Q حفظ می کنند (به دلیل ارزش ثابت h).
فلوچارت دقیق طرح پیشنهادی DIAQ در شکل ۲ نشان داده شده است. مراحل الگوریتم مربوط به ICIC جدید سایه دار هستند و از خطوط نقطه چین استفاده می شود. بقیه فلوچارت یک فرآیند DSA مبتنی بر Q-learning توزیع شده شرح داده شده در بخش ۳ را توصیف می کند. بلوک های سایه دار با خطوط تو پر نشان دهنده توابعی هستند که فرآیند RL، یعنی به روز رسانی Q-table را انجام می دهند.
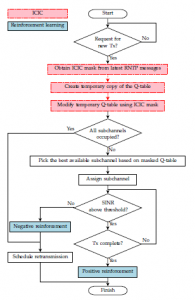
شکل ۲٫ نمودار جریان پیشنهادی طرح ICIC تسریع کننده Q-learning (DIAQ)
[۱] Distributed Heuristically Accelerated Q-Learning
[۲] spectrum
[۳] real-time
برای دانلود فایل پاورپوینت آن روی لینک روبرو کلیک کنید : دانلود
دیدگاهتان را بنویسید