







پروژه تشخیص پیامک های اسپم با متلبسهشنبه 05, فوریه 2019

پروژه تشخیص پیامک های اسپم با متلب
سایت همیارپروژه یک پروژه بسیار کاربردی را در حوزه پروژه تشخیص پیامک های اسپم با متلب انجام داده و آن را جهت دانلود شما عزیزان در سایت قرار داده است.جهت خرید و دانلود پروژه توضیحات زیر را مطالعه نمایید.این پروژه در انجام پروژه مهندسی برق میتواند یک کار آموزشی باشد.
نرم افزار متلب :
مَتلب (به انگلیسی: MATLAB) یک محیط نرمافزاری برای انجام محاسبات عددی و یک زبان برنامهنویسی نسل چهارم است. واژهٔ متلب هم به معنی محیط محاسبات رقمی و هم به معنی خود زبان برنامهنویسی مورد نظر است که از ترکیب دو واژهٔ MATrix (ماتریس) و LABoratory (آزمایشگاه) ایجاد شدهاست. این نام حاکی از رویکرد ماتریس محور برنامه است، که در آن حتی اعداد منفرد هم به عنوان ماتریس در نظر گرفته میشود.
متلب نرم افزاری برای انجام پروژه برق قدرت و انجام پروژه های مهندسی صنایع ، انجام پروژه مهندسی کامپیوتر ، انجام پروژه مهندسی مکانیک ، انجام پروژه مهندسی شیمی ، انجام پروژه مهندسی پزشکی و ….است.

توضیحات پروژه :
عنوان : پروژه تشخیص پیامک های اسپم با متلب
توضیح :
میخواهیم با استفاده از یک دیتاست حاوی پیامکهای هرز و معمولی، اقدام به آموزش چندین مدل دستهبندی کنیم. این مدلها شامل درخت KNN ، بیز ساده، درخت تصمیم و Bagging هستند. آنگاه از روش خوشهبندی Kmeans برای تقسیمبندی دادهها در دو گروه استفاده میکنیم. مراکز هر خوشه را به دست آورده و با استفاده از این مراکز خوشه، اقدام به دستهبندی دادههای تست میکنیم.
پردازش متن:
دیتاست حاضر حاوی پیامکهایی است که به صورت انگلیسی موجود هستند. ما از دیتاست English_big برای کار خود استفاده کردهایم چون دیتاست بزرگتری است. این دیتاست ۱۳۲۴ پیامک را شامل میشود که تنها ۳۲۲ نمونه آن اسپم است. در پیادهسازیها نیاز داریم که این پیامکها را پردازش کنیم. مراحل پردازش به صورت زیر هستند.
- ابتدا پیامکها را خط به خط میخوانیم.
- سپس حروف بزرگ انگلیسی را به حروف کوچک تبدیل میکنیم.
- توکنبندی کلمات
- علامتهایی که حرف نیستند را حذف میکنیم. مثل ؟، !، @ و غیره
- کلمات کمتر از ۲ حرف و بیش از ۱۰ حرف را حذف میکنیم.
- حذف کلمات stopwords از متن پیامکها
- ریشهیابی کلمات انگلیسی و تبدیل کلمات مشتق به ریشه کلمات
- دوباره کلمات Stopwords را حذف میکنیم چون ممکن است ریشههایی از کلمات Stopwords از مرحله قبل به وجود آیند
- ساخت Bog of words در متلب
- استخراج ویژگیهای tfidf از bag of words
مدلهای دستهبندی:
بیز ساده:
روش بیز ساده، یک روش بر مبنای تئوری بیز است. ایده اصلی در این روش این است که ویژگیها از یکدیگر مستقل هستند، درنتیجه مسئله و حل آن بسیار ساده میشود.
و درنتیجه برای محاسبه احتمال یک داده تست، نیازی به دانستند ارتباط بین ویژگیها نیست. بلکه تنها کافی است که احتمال هر ویژگی را محاسبه کرده و با ضرب این احتمالات (چون ویژگیها مستقل هستند) احتمال نهایی به دست میآید

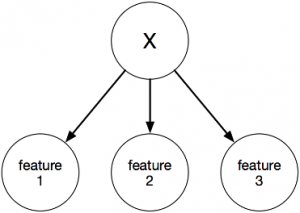
درخت تصمیم:
درخت تصمیم از روشهای مبتنی بر تصمیمگیری و با ساختار درختی است که یک ایده بسیار جالب در مورد مسئله دارد. ایده اصلی این روش این است که دنیا ذاتاً ساده است. این روش خود را درگیر پیچیدگیهای مسئله و ریاضیات سنگین نمیکند و بهطور ذاتی علاقه دارد تا مسئله را ساده ببیند و ساده حل کند.
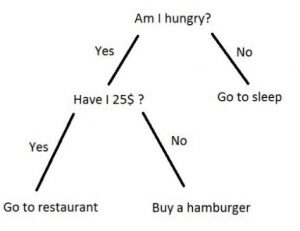
سادگی ذکر شده برای ما انسانها بسیار قابللمس است. اگر به شکل درخت تصمیم بالا نگاه کنیم، بهخوبی متوجه میشویم که این روش در حال انجام چه کاری است و چگونه دادههای کلاسها را جداسازی میکند.
روند کار این روش به این صورت است که نودهای درخت، ویژگیها هستند و برگهای درخت، برچسب کلاسها. در نودها و با توجه به نوع ویژگی و مقدار آن، که در نود مربوطه وجود دارد، درخت اقدام به تقسیمبندی دادهها میکند. سپس در زیرشاخه بعدی، یک ویژگی دیگر انتخاب شده و دوباره دادهها تقسیمبندی میشوند و این روند آنقدر ادامه پیدا میکند که یا تمامی ویژگیها برای تصمیمگیری دخیل شوند و یا درخت بتواند با تعداد محدودی از ویژگیها، نوع دسته را مشخص کند.
نزدیکترین همسایگی:
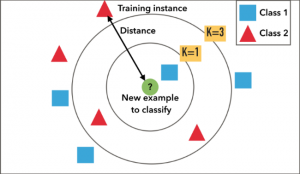
روش نزدیکترین همسایگی یا بهاختصار KNN ، یک روش بدون آموزش است که به آن روش تنبل نیز میگویند. این روش هیچ آموزشی ندارد و دادههای تست را تنها با مقایسه فاصله بین داده تست و دادههای آموزشی دستهبندی میکند. روند کار این الگوریتم به این صورت است که یک داده تست را دریافت میکند. سپس یک همسایگی نزدیک در اطراف این داده تست فرض میکند. تعداد این همسایگیها توسط ما قابلتعریف است. انتخاب این همسایگیها باید بر اساس معیار فاصلهای انجام شود که معمولاً از معیار فاصله اقلیدسی استفاده میشود.
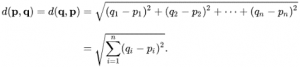
سپس در یک عملیات تصمیمگیری، مشخص میشود که این داده تست به کدام کلاس تعلق دارد. داده تست به کلاسی تعلق دارد که در یک همسایگی آن، بیشترین داده آموزشی مربوط به آن کلاس وجود داشته باشد.
bagging:
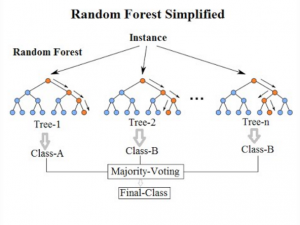
زمانی که صحبت از دادههای غیر بالانس و یا بیش برازش (overfitting) مدلهای یادگیری ماشین میشود، بهترین راهحلی که به ذهن میرسد، استفاده از جنگل تصادفی است که یکی از روشهای bagging محسوب میشود. جنگل تصادفی متشکل از چندین درخت تصادفی است که هر درخت تعدادی از ویژگیهای مسئله را کنترل میکند. بهعبارتدیگر تعدادی ویژگی را به صورت تصادفی انتخاب میکنیم با آن یک درخت تصمیم برای مسئله میسازیم و بهعنوان یکی از درختهای جنگل تصادفی در نظر میگیریم. این درختها را به تعداد مورد نظر میسازیم.

در پایان کار، با یک رایگیری، اقدام به پیدا کردن کلاس هر داده میکنیم.
نحوه محاسبه معیارها:
از چند معیار برای محاسبه عملکرد دستهبندی و خوشهبندی استفاده میکنیم. این معیارها از روی ماتریس درهمریختگی محاسبه میشوند.
نتایج بخش دستهبندی:
بعد از اجرای پیادهسازیهایی که برای بخش دستهبندی انجام دادهایم، خروجیها به صورت زیر نمایش داده میشوند. با توجه به مقادیر Accuracy مبینیم که مدل bagger از بقیه مدلها بهتر بوده است. پس نشان میدهد که ترکیب تعدادی درخت تصادفی میتواند از درخت تصادفی و سایر روشهایی که در این تمرین استفاده کردهایم بهتر باشد. بعدازآن بیز ساده بیشترین دقت را داشته است. بااینکه بیز ساده فرض مستقل بودن ابعاد را در نظر دارد بااینحال از لحاظ دقت دستهبندی خوب عمل کرده است. بدترین مدل مربوط به knn است که تنها ۸۱% دقت داشته است و نسبت به سایر مدلها دقت بسیار پایینی دارد.
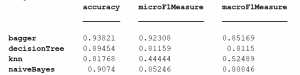
اگر به مقادیر microF1Measure نگاه کنیم متوجه میشویم که تحملپذیری روش bagger روی تغییر سایز دیتاست بسیار بالاست و نسبت به سایر روشها این تحملپذیری بسیار محسوس است. بدترین مقدار نیز مربوط به روش knn است که مشخص میکند قدرت این روش بسیار حساس به تعداد نمونههاست و اگر تعداد نمونههای آموزشی کم شود، باعث کاهش کیفیت دستهبندی خواهد شد.
و در پایان اگر به macroF1Measure نگاه کنیم متوجه میشویم که باز هم روش bagger بهترین عملکرد را دارد و نشاندهنده این است که این روش روی دیتاستهای متفاوت میتواند عملکرد قابلقبول خود را تا اندازه ۰٫۸۵ حفظ کند. اما این مورد در مورد روش knn بههیچوجه صادق نیست. روشهای بیز ساده و درخت تصمیم هم، تا حد قابلقبولی روی دیتاستهای متفاوت میتوانند کارایی خود را حفظ کنند و نتایج پایداری را بدهند.
نتایج بخش خوشهبندی:
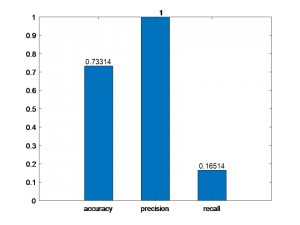
بعد از اجرای پیادهسازی خوشهبندی، نتایج به صورت زیر حاصل میشوند. شکل زیر سه معیار دقت، صحت و نرخ بازیابی را نشان میدهند. بااینکه صحت دستهبندی مقدار حداکثر خود، یعنی ۱ را داشته است اما از لحاظ دقت خوب عمل نکرده است. پس نشان میدهد که خوشهبندی توانایی جداسازی و تقسیمبندی دادهها در دسته مربوط به خودشان را در حد ایده آلی که ما میخواهیم ندارد. این موضوع را از نرخ بازیابی نیز میتوان متوجه شد که خوشهبندی نتوانسته است در مورد یکی از کلاسها عملکرد قابلقبولی داشته باشد.
برای مقایسه بهتر، ماتریس درهمریختگی برچسبگذاری به روش خوشهبندی را با ماتریس درهمریختگی درخت تصمیم مقایسه میکنیم.
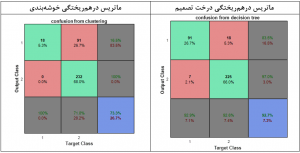
با توجه به ماتریسیهای جدول زیر، مشخص است که روش خوشهبندی مقدار کمی از دادههای کلاس ۱ را درست دستهبندی کرده است. یعنی تنها ۱۸ نمونه و ۹۱ نمونه از کلاس ۱ را اشتباهاً در کلاس ۲ قرار داده است. ولی در مورد کلاس ۲ بهخوبی عمل کرده است و تمامی نمونههای کلاس ۲ را بهعنوان کلاس ۲ در نظر گرفته است.پس خوشهبندی توانایی مناسبی در تقسیمبندی کلاس ۱ ندارد.
اما اگر به ماتریس درهمریختگی دخت تصمیم نگاه کنیم، متوجه میشویم که این روش هم دادههای کلاس ۱ و هم دادههای کلاس ۲ را تا حد امکان درست دستهبندی کرده است. همین موضوع تفاوت بین روشهای خوشهبندی که بدون نظارت آموزش میبینند را با روشهای با نظارت نشان میدهد. پس متوجه میشویم که داشتن برچسبها و آموزش مدلها با توجه به برچسبهای آموزشی تا چه حد میتواند دقتها را افزایش دهد.
نرم افزار پروژه:
این پروژه با نرم افزار متلب انجام شده است.
گزارش و توضیحات پروژه:
این پروژه دارای یک فایل ورد و یک فایل پی دی اف توضیح کامل کار به همراه توضیح خط به خط کدها می باشد.
نحوه خرید و دانلود فایل پروژه:
برای دانلود فایل های این پروژه ابتدا بروی دکمه خرید کلیک نمایید.
بعداز مشاهده فاکتور و پرداخت هزینه از طریق درگاه سایت لینک دانلود فایلهای پروژه“پروژه تشخیص پیامک های اسپم با متلب”برای شما نمایش داده می شود.
فایلهای پروژه به صورت ۱۰۰% تست شده و تمامی فایل ها سالم می باشد.
سفارش پروژه مشابه :
درصورتی که پروژه ای مشابه دارید که میخواهید بصورت سفارشی برایتان انجام شود میتوانید در تلگرام یا واتساپ شماره ۰۹۱۹۰۹۷۴۵۵۳ درخواستتان را ثبت نمایید و به صفحه انجام پروژه سیمولینک مراجعه کرده و پروژه خود را سفارش دهید.
خرید پروژه های مشابه :
سایت همیارپروژه صدها پروژه آماده متلب را انجام داده و برای خرید با قیمت بسیار مناسب در سایت بارگذاری نموده است.برای مشاهده این پروژه ها میتوانید به صفحه پروژه های آماده متلب مراجعه نمایید.
دیدگاهتان را بنویسید