







دادهکاوی با تمرکز بر دستهبندی و خوشهبندی در دیتاست ارزیابی خودرو در رپیدماینرسهشنبه 11, سپتامبر 2018

دادهکاوی با تمرکز بر دستهبندی و خوشهبندی در دیتاست ارزیابی خودرو در رپیدماینر
سایت همیارپروژه یک پروژه بسیار کاربردی را در حوزه دادهکاوی با تمرکز بر دستهبندی و خوشهبندی در دیتاست ارزیابی خودرو در رپیدماینر انجام داده و آن را جهت دانلود شما عزیزان در سایت قرار داده است.جهت خرید و دانلود پروژه توضیحات زیر را مطالعه نمایید.
نرم افزار رپیدماینر :
RapidMiner ۹٫۱۰ x86/x64 رپیدماینر؛ یک محصول نرم افزاری قدرتمند و حرفهای در زمینه علم داده است که توسط شرکتی با همین نام ساخته شده و با دارا بودن یک محیط گرافیکی یکپارچه و زیبا، به کاربران خود این امکان را میدهد که بتوانند به آمادهسازی داده برای اهداف یادگیری ماشین، یادگیری عمیق، متن کاوی، تجیزه و تحلیل و همینطور پیشبینی بپردازند. دادهکاوی با استفاده از رپیدماینر، یکی از محبوبترین و پرطرفدارترین شیوهها در حوزه دادهکاوی است که حتی بدون نیاز به دانش برنامهنویسی هم میتوان از آن استفاده کرد. داده کاوی در بین دانشجویان و شرکتهای بزرگ از اهمیت و محبوبیت بالایی برخوردار است؛ مخصوصا اینکه این روزها، داده و توانایی تحلیل و پیشبینی آن از جمله داراییهای ارزشمند و گرانبهای هر سازمان محسوب میشود. افزایش رقابت در بین شرکتها، هدفمند شدن تصمیمگیری مدیران، نیاز به کاهش هزینههای سازمانی و بالا بردن درآمد و در نتیجه افزایش سود از جمله عواملی هستند که نیاز به داده کاوی و پیادهسازی مدلهای مبتنی بر یادگیری ماشین را بیش از پیش افزایش دادهاند.

توضیحات پروژه :
عنوان : دادهکاوی با تمرکز بر دستهبندی و خوشهبندی در دیتاست ارزیابی خودرو در رپیدماینر
توضیح :
در این پروژه هدف انجام مدل های مختلف داده کاوی که شامل الگوریتم های دسته بندی و خوشه بندی و همچنین پیش پردازش داده ها است، می باشد. در واقع در راستای بررسی تفاوت ها و دقت مدل های مختلف داده کاوی یک دیتاست از مجموعه دادگان uci انتخاب شده و پس از انجام پیش پردازش روی داده ها، داادگان را جهت دسته بندی به الگوریتم های مختلف دسته بندی داده و روی هر کدام دقت را بدست آورده و در نهایت دقت آن ها را باهم در جدول و نمودار مقایسه نمودیم. سپس باری دیگر دادگان را برای خوشه بندی به الگوریتم های مختلف داده و از نظر عملکرد آن ها را با فاصله درون کلاسی بررسی می کنیم.
ویژگی داده ها:
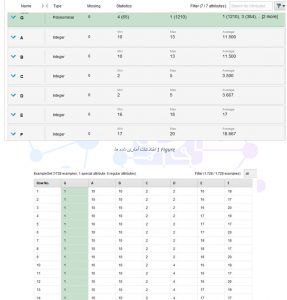
در این پروژه از مجموعه دادگان car Evaluation استفاده شده است. این دیتاست متعلق به مجموعه UCI می باشد و ویژگی های آن به صورت زیر می باشد:

داده ها در رپیدماینر:
پیش پردازش داده ها:
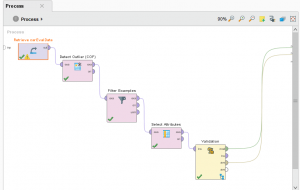
همانطور که در شکل قسمت قبل دیده می شود داده ها داری مقادیر گمشده نمی باشند. به همین دلیل پیش پردازش داده ها را به یافتن مقادیر outlier اختصاص می نماییم. با توجه به اینکه تعداد ویژگی داده ها ۶ عدد می باشد نیازی به کاهش بعد با توجه به حجم بالای نمونه ها نیز نمی باشد. پس با استفاده از نود detect outlier نمونه های پرت را پیدا نموده و سپس آن ها را با نود filter Examples فیلتر می نماییم.
جهت خارج کردن ویژگی های اضافه که هنگام یافت outlier ها به ویژگی های اصلی داده ها اضافه شد از نود Select Attribute استفاده شده است.
برای تقسیم داد ها به دو بخش آموزش و تست از نود validation استفاده شده است در قسمت تنشیمات این نود ۰٫۷ داده ها برای آموزش و ۳۰ درصد باقی برای تست در نظر گرفته شده است.
نحوه خرید و دانلود فایل پروژه:
برای دانلود فایل های این پروژه ابتدا بروی دکمه خرید کلیک نمایید.
بعداز مشاهده فاکتور و پرداخت هزینه از طریق درگاه سایت لینک دانلود فایلهای پروژه “دادهکاوی با تمرکز بر دستهبندی و خوشهبندی در دیتاست ارزیابی خودرو در رپیدماینر” برای شما نمایش داده می شود.
فایلهای پروژه به صورت ۱۰۰% تست شده و تمامی فایل ها سالم می باشد.
سفارش پروژه مشابه
درصورتی که پروژه ای مشابه دارید که میخواهید بصورت سفارشی برایتان انجام شود میتوانید به صفحه سفارش پروژه رپیدماینر مراجعه کرده و پروژه خود را سفارش دهید.
خرید پروژه های مشابه :
سایت همیارپروژه صدها پروژه آماده رپیدماینر را انجام داده و برای خرید با قیمت بسیار مناسب در سایت بارگذاری نموده است.برای مشاهده این پروژه ها میتوانید به صفحه داده کاوی در نرم افزار رپیدماینر (Rapid Miner) مراجعه نمایید.