







پردازش دادههای عددی بزرگ با NumPy و Pandas در پایتونسهشنبه 28, مه 2019

پردازش دادههای عددی بزرگ با NumPy و Pandas در پایتون
سایت همیارپروژه یک پروژه بسیار کاربردی را در حوزه پردازش دادههای عددی بزرگ با NumPy و Pandas در پایتون انجام داده و آن را جهت دانلود شما عزیزان در سایت قرار داده است.جهت خرید و دانلود پروژه توضیحات زیر را مطالعه نمایید.
پایتون :
پایتون یک زبان برنامه نویسی متن باز (open source) است که با داشتن هزاران کتابخانه در حوزه های مختلف قدرت بسیار زیادی را کسب نموده است.پایتون جزو محبوب ترین و سریعترین زبان های سطح بالاست.از جمله پروژه های قابل انجام با پایتون میتوان به پروژه های مهندسی نرم افزار ، هوش مصنوعی ، مهندسی برق ، مهندسی مکانیک ، مهندسی پزشکی ، هک و نفوذ ، طراحی سایت ، داده کاوی و … اشاره نمود.

توضیحات پروژه :
عنوان : پردازش دادههای عددی بزرگ با NumPy و Pandas در پایتون
توضیح :
استفاده از لایبرری های Numpy و Pandas در راستای Data Science برای کار موثر و عملیات سریع بر روی داده های بزرگ عددی محیط تست و اجرا: Jupyter Notebook نامگذاری متغیرها باید با مسمی )به زبان انگلیسی( باشد و متناسب با مقادیری که در آن قرار می گیرد. در صورت انتخاب نام چند کلمه ای برای یک متغیرف آن نام باید با حرف کوچک شروع شود و هر کلمه بعد از آن با حرف بزرگ. به عنوان مثال قتی کل فایل متن یک کتاب را در پایتون وارد می کنید و متن را در یک استرینگ قرار میدهید نام آن اسرینگ می تواند به شکل wholeTextString انتخاب شود.
کلیه کدهای نوشته شده با برنامه های هوش مصنوعی سفارشی شده، ” کپی یابی” و ” تکراری یابی” خواهند شد و هیچگونه دانلود و یا نسخه برداری همانند اصل، در پروژه وجود ندارد. همچنین میتوان با اعمال تغییراتی در تعداد خطوط کد، نام متغیرها، نام کلاس ها ، جابجایی های مفهومی و … از وقوع این مساله جلوگیری شود.
جزئیات پروژه:
در این گزارش قصد داریم تا با استفاده از توابع کتابخانه های Numpy و Pandas اقدام به داده کاوی دیتاست مورد نظر کنیم. برای این منظور کلاسی تعریف میکنیم به نام Table که این کلاس حاوی تعدادی تابع است. این توابع عملیات هایی را روی دیتاست انجام میدهند که این امکان را به ما میدهند که از دیتاست اطلاعات خاصی را استخراج کنیم.
همچنین این کلاس شامل دو خصیصه است که در یکی از این خصیصه ها اطلاعات هدر دیتاست (اسامی ویژگی ها) و در دیگری اطلاعات عددی دیتاست قرار گرفته اند. دلیل اینکه اطلاعات دیتاست را در خصیصه های یک کلاس قرار میدهیم این است که با استفاده از توابع داخلی آن کلاس بتوانیم به این خصیصه به صورت محلی دسترسی داشته باشیم و نیاز به ارسال اطلاعات از یک کلاس به کلاس دیگر نباشد.
این گزارش دو دو بخش طراحی شده است. بخش اول، طراحی توابعی با استفاده از کتابخانه Numpy است که عملیات استخراج اطلاعات را با استفاده از این کتابخانه انجام بدهیم و سپس با توجه به کلاسی که نوشته ایم، بتوانیم مشخصات آماری از دیتاست استخراج کنیم.
در بخش دوم گزارش، تمامی موارد بالا را با استفاده از کتابخانه Pandas انجام میدهیم که در مقایسه با کتابخانه Numpy بسیار حرفه ای تر و ساده است.
البته باید توجه کرد که این دو کتابخانه در کنار یکدیگر میتوانند قوی باشند و مسیر داده کاوی را تسهیل کنند.
شرح مساله:
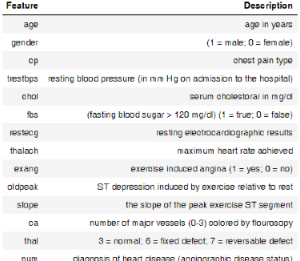
فایل csv پیوست حاوی اطلاعات پزشکی ۲۹۳ بیمار است که شرح سرستونهای اطلاعات به شکل زیر است:
نحوه خرید و دانلود فایل پروژه:
برای دانلود فایل های این پروژه ابتدا بروی دکمه خرید کلیک نمایید.
بعداز مشاهده فاکتور و پرداخت هزینه از طریق درگاه سایت لینک دانلود فایلهای پروژه“پردازش دادههای عددی بزرگ با NumPy و Pandas در پایتون”برای شما نمایش داده می شود.
فایلهای پروژه به صورت ۱۰۰% تست شده و تمامی فایل ها سالم می باشد.
سفارش پروژه مشابه :
درصورتی که پروژه ای مشابه دارید که میخواهید بصورت سفارشی برایتان انجام شود میتوانید به صفحه انجام پروژه پایتون مراجعه کرده و پروژه خود را سفارش دهید.
خرید پروژه های مشابه :
سایت همیارپروژه صدها پروژه آماده پایتون را انجام داده و برای خرید با قیمت بسیار مناسب در سایت بارگذاری نموده است.برای مشاهده این پروژه ها میتوانید به صفحه پروژه های آماده پایتون مراجعه نمایید.
دیدگاهتان را بنویسید