







بررسی قیمت صادراتی محصول زعفران با استفاده از سه مدل ARIMA، ANN و ANFIS در متلبسهشنبه 20, آوریل 2021

بررسی قیمت صادراتی محصول زعفران با استفاده از سه مدل ARIMA، ANN و ANFIS در متلب
در ادامه آموزش های سایت همیارپروژه برنامه نویسی متلب ارائه خواهد شد .آموزشها از مقدماتی تا پیشرفته ادامه دارد و ما به شما کدنویسی در نرم افزار متلب را رایگان یاد خواهیم داد. با ما همراه باشید.

قیمت صادراتی محصول زعفران با استفاده از سه مدل ARIMA، ANN و ANFIS
تجزیه وتحلیل دادههای این تحقیق و آزمون فرضیات آن توسط نرم افزار Excel و EVIEWS 8 و همچنین نرم افزار MATLAB انجام شده است. به این ترتیب که اطلاعات فراهم شده توسط پایگاههای اطلاعاتی ابتدا در نرم افزار Excel دسته بندی و مرتب سازی شده است و سپس به نرم افزارهای EVIEWS 8 و MATLAB منتقل گردیده تا آزمونهای آماری مورد نظر بر روی آنها انجام شود. در این تحقیق قیمت صادراتی محصول زعفران با استفاده از سه مدل ARIMA، ANN و ANFIS پیش بینی شده و کاراترین مدل در این زمینه با استفاده از معیارهای کارایی سنجی معرفی میگردد. به منظور مقایسه قدرت پیش بینی و انتخاب بهترین روش پیش بینی، از معيارهاي مختلف از جمله ميانگين مربعات خطا (MSE)، ريشه ميانگين مربعات خطا(RMSE)، ميانگين قدرمطلق خطا (MAE) و درصد ميانگين قدر مطلق خطا بر اساس روابط ارزیابی کرد:
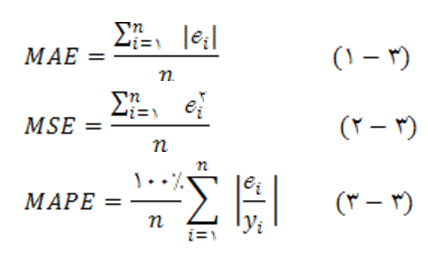
در این روابط n تعداد پیش بینیها، iℯ خطای پیش بینی است که از تفاوت مقادیر پیش بینی شده و مقادیر واقعی بدست میآید و yt مقدار واقعی است. پس از اينکه پيش بيني به وسيله هر سه روش ARIMA، ANN و ANSIS انجام شد در مرحله بعد به مقايسه نتايج اين سه روش و ميزان خطاي آنها پرداخته میشود تا در نهايت بتوان بهترين روش را انتخاب نمود.
روش مدل سازي خود رگرسيون ميانگين متحرک انباشته (ARIMA):
طبق ديدگاه مدلهاي سريهاي زماني يک متغيره، را ميتوان صرفاَ تابعي از مقاديرگذشته آن در نظر گرفت. به عبارت ديگر، مقادير متغیر مورد بررسی در دورههاي قبل حاوي کليه اطلاعات لازم مربوط به عوامل تعيين کننده آن متغیر بوده است؛ از این رو میتواند آن متغیر را توضيح داده، مقادير آتي آن را پيش بيني نمايد. مساله مهم در اين روش، تنها تعيين تعداد وقفههاي بهينه متغیر و همچنين تشخيص ساختار متغير تصادفي در مدل است. معمولاً براي تخمين الگوهاي ARIMAاز روش باکس- جنکينز استفاده ميشود که داراي چهار مرحله است. مرحله اول كه شناسايي آزمايشي نام دارد و با استفاده از تابع خود همبستگي نمونه و تابع جزئي خودهمبستگي نمونه انجام میگيرد. به محض اينكه مدل به طور آزمايشي شناسايي شد، وارد مرحله دوم شده و به تخمين پارامترها میپردازد (مرحله تخمين). مرحله سوم، مرحله تشخيص دقت برازش نام دارد كه در اين مرحله كفايت شناسايي آزمايشي و تخميني كه در مورد مدل انجام شده است، مورد ارزيابي قرار میگيرد. اگر نامناسب بودن مدل به اثبات برسد، مدل بايد مورد تعديل و اصلاح قرار گيرد. زماني كه مدل نهايي حاصل میشود، در مرحله چهارم از آن میتوان به منظور پيش بيني مقادير آينده سري زماني استفاده كرد (مرحله پيش بيني) استفاده از روش باکس – جنکينز، نيازمند در دسترس بودن يک سري پايا يا يک سري زماني که پس از تفاضل گيري پايا شود، است. زيرا هدف باکس – جنکينز، شناسايي و تعيين يک مدل آماري است که ميتوان آن را مدل توليد کننده دادههاي نمونه واقعي از فرايند تصادفي تعبير کرد. در تحقيق حاضر براي دادههاي سري زماني قیمت محصول زعفران، این روش مورد استفاده قرارگرفته است. برای پیش بینی قیمت زعفران با استفاده از متد باکس جنکينز مدل ARIMA(4,1,4) انتخاب شده است. نتایج این مدل نیز در نمودار ۱ به تصویر کشیده شده است.
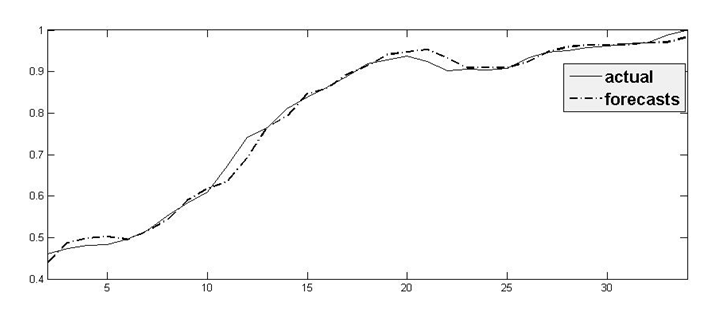
نمودار ۱ مقادیر واقعی و پیش بینی قیمت زعفران را در دوره برون نمونه ای ارائه میکند. در این نمودار مقادير پيش بيني به صورت خطوط نقطه چین ترسیم شده است نکته قابل توجه اين است که در دوره افزایش مقادیر واقعی، مدل دارای بیشترین خطای برآورد میباشد
-
شبکههاي عصبي مصنوعي (ANN )
شبكههاي عصبي مصنوعي توابعي جامع و انعطاف پذير و ابزاري قدرتمند براي تجزيه و تحليل دادهها و مدل سازي روابط غير خطي، با درجه صحت بالا هستند. مهمترين ويژگي مدلهاي ANN آزادي آنها از فروض آماري مربوط به متغيرها، استفاده از روشهاي محاسباتي موازي و غير خطي بودن آنهاست .
-
مراحل طراحي مدل شبکههاي عصبي مصنوعي
در اين قسمت به ترتيب مراحل طراحي و انتخاب شبکه توضيح داده خواهد شد و سپس نتايج حاصل از بهترين شبکه در پيش بيني آورده ميشود.
مرحله اول: اولين مرحله شناسايي نوع شبکه و آزمون آن است. در اين مطالعه از شبکههاي عصبي پيشرو استفاده ميشود. زيرا براي تقريب توابع، شبکههاي پيشرو نسبت به شبکههاي ديگر بهتر عمل ميکنند. در اين نوع شبکه خروجي هر لايه، ورودي لايه بعدي است و جزء بهترين شبکه از نوع يادگيري با ناظر يا سرپرستي شده است. آموزش اين نوع شبکه رو به جلو، آموزش پس انتشار خطاست که در قسمت nntool يا همان جعبه ابزارنرم افزار MATLAB انتخاب ميشود.
مرحله دوم: دومين مرحله انتخاب وروديهاي مدل يا همان واحدهاي لايه ورودي و يا به عبارت ديگر، متغيرهاي توضيحي مدل است. در اکثر مسائل سريهاي زماني با شکل ARIMA(p,d,q) مقدار، صفر، ۱، و يا ۲ است و به ندرت مقدار ۳ يا ۴ به خود ميگيرد. در اين تحقيق براي اطمينان، مرتبط بودن هر مشاهده را تا ۶ مشاهده قبل از آن بررسي گردید.
مرحله سوم: در اين مرحله ابتدا تقسيم دادهها به چهار دسته، آموزش، اعتبارسنجی، آزمون و پيش بيني (گذشته نگر و آينده نگر) انجام و به دليل خطاي بالاي شبکه، دادههاي اعتبارسنجی نيز به آموزش اضافه شد، بدين معني که قسمت اعظم دادهها براي آموزش و ما بقي براي آزمون و پيش بيني اختصاص داده شدند. واضح است که در تقسيم دادهها با حالات متفاوتي مواجه هستيم که در اين تحقيق، حالتهاي بسيار زياد و متغيري از تعداد دادهها در اين چهار دسته آزمايش شده اند.
مرحله چهارم: مرحله تعيين متغيرهاي ورودي يا تعداد تأخيرهاست. در اين مرحله، متغير توضيحي وقفههای قيمت محصولات کشاورزی به عنوان متغير ورودي وارد شبکه ميشوند.
مرحله پنجم: در اين مرحله، تعداد لايههاي شبکه انتخاب ميشود. شبکهاي که براي اين تحقيق انتخاب شد داراي چهار لايه است: لايه ورودي، دو لايه مخفي و لايه خروجي. تعداد بيشتر لايهها شبکه را پيچيده ميکند و تنها در صورتي که خروجيهاي بهتري از شبکه دريافت شود بايد اقدام به افزايش لايهها نمود.
مرحله ششم: در اين مرحله، توابع محرک، که در بخش سوم توضيح داده شده اند، براي لايههاي شبکه انتخاب ميشوند. در لايه مخفي از تابع تانژانت سيگموييد و در لايه خروجي از تابع خطي استفاده شده است.
مرحله هفتم: در اين مرحله، تعداد نرونهاي لايه مخفي تعيين ميشوند. همان گونه که در بخش سوم توضيح داده شد، تعداد نرونها بايستي با دقت کافي تعيين شود تا دچار مشکل برازش بيش از حد نشويم. تعداد زياد نرونها در لايههای مخفي گرچه باعث پايين آمدن خطاي آموزش ميشود، اما از طرف ديگر، خطاي آزمون را افزايش ميدهد. بنابراين معمولاَ از تعداد کم نرون شروع ميکنند و در صورت بهبود جوابها نرونها افزايش مييابد. در اين تحقيق، تعداد نرونها از ۱ تا ۴۰ نرون در لايههای مخفي آزمايش شده است.
مرحله هشتم: در اين مرحله، الگوريتم آموزش و تعداد تکرار برابر ۵۰۰ انتخاب شد، که اين مقدار خطا را کاهش ميدهد. ميزان خطاي پيش بيني، ميانگين مربعات خطا (MSE) و خطاي مطلوب صفر در نظر گرفته شده است.
با توجه به مراحل ذکر شده بالا براي این مطالعه حدود ۱۸۰ شبکه طراحي و هرکدام چندين بار آزمون شد و در نهايت دو شبکه عصبي با ساختارهای زیر طراحی و انتخاب گردید.

-
پیش بینی قیمت زعفران به روش شبکههاي عصبي مصنوعي (ANN )
نمودار ۲ مقادیر واقعی و نتایج استفاده از شبکه عصبی در پیش بینی سری زمانی قیمت صادرانی زعفران را نشان میدهد.

نکته قابل توجه در نمودار ۲ این است که این نمودار نسبت به نمودار قبلی (مدل ARIMA) مربوط به پیش بینی قیمت زعفران انطباق بیشتر با منحنی مقادیر واقعی دارد.
-
مدل ANFIS در پيش بيني سري زماني قیمت محصولات زعفران
نمودار ۳ نیز نتایج استفاده از مدل ANFIS در پیش بینی قیمت صادراتی زعفران را نمایش میدهد.

همانطور که از نمودار ۳ قابل مشاهده است مقادیر پیش بینی در این مدل به مقادیر واقعی بسیار نزدیک هستند و با استفاده از مدل ANFIS توانسته ایم نتایج به ظاهر بهتری در پیش بینی قیمت زعفران نسبت به مدلهای قبل بدست آوریم با این حال به منظور ارزیابی نتایج مدلها باید از معیارهای کارایی سنجی مانند MSE و MAE استفاده کرد که در قسمت بعد به این امر پرداخته میشود
-
کارايي سنجي
همانطور که پیش تر بیان گردید در این تحقیق به منظور مقایسه قدرت پیش بینی و انتخاب روش پیش بینی کاراتر، از معيارهاي ميانگين مربعات خطا (MSE)، ميانگين قدرمطلق خطا (MAE) و درصد ميانگين قدر مطلق خطا(MAPE) پس از اينکه پيش بيني به وسيله هر سه روش ARIMA و ANN و ANFIS انجام شد در اين بخش به مقايسه نتايج اين سه روش و ميزان خطاي آنها پرداخته میشود تا در نهايت بتوان بهترين روش را انتخاب نمود. جدول شماره ۴ نتایج این بخش را نشان میدهد.
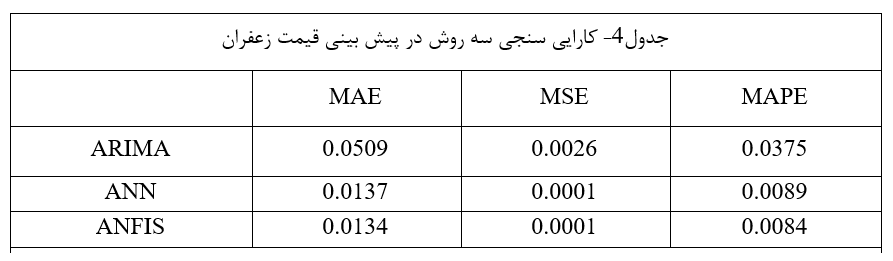
همانطور که در جدول ۴ نشان داده شده است معیارهای سنجش کارایی در روش پیش بینی با استفاده از مدل ANFIS به ترتیب مقادیر ۰٫۰۱۳۴، .۰٫۰۰۰۱ و ۰٫۰۰۸۴را اختیار کرده اند که در میان روشهای بکار برده شده کمترین خطا را نشان داده و بنابراین بهترین پیش بینیها و کارایی را داشته است. در طرف مقابل؛ مدل تک متغیره (ARIMA) دارایی بیشترین خطا و به عبارتی کمترین کارایی میباشد. همچنین در این بین، مدل ANN نیز از کارایی نسبی برخوردار میباشد.
-
تحلیل فرضیات:
- مدلهای عصبی-فازی (ANFIS)، شبکه عصبی (ANN) و خود رگرسیونیARIMA میتوانند قیمت صادراتی محصول زعفران را به صورت مناسبی پیش بینی نمایند.
- مدل عصبی-فازی (ANFIS) در پیش بینی قیمت صادراتی محصول زعفران کاراتر از دو مدل شبکه عصبی (ANN) و خود رگرسیونی ARIMA میباشد.
- مدل مدل شبکه عصبی (ANN) در پیش بینی قیمت صادراتی محصول زعفران کاراتر از مدل اقتصاد سنجی خود رگرسیونی ARIMA میباشد.
نتایج نشان میدهد معیارهای سنجش کارایی در روش پیش بینی قیمت صادراتی زعفران با استفاده از مدل ANFIS در میان روشهای بکار برده شده کمترین خطا را نشان داده و بنابراین بهترین پیش بینیها و کارایی را داشته است. در طرف مقابل؛ مدل تک متغیره (ARIMA) دارایی بیشترین خطا و به عبارتی کمترین کارایی میباشد. همچنین در این بین، مدل ANN نیز از کارایی نسبی برخوردار میباشد. بنابراین فرضیات تحقیق در ارتباط با پیش بینی قیمت صادراتی زعفران نیز مورد تایید قرار میگیرند
در اینجا آشنایی با محیط متلب بخش صد و بیست و سوم به پایان رسیده است و در آموزش های بعدی به مباحث دیگر آموزش متلب می پردازیم. همچنین از شما مخاطبین عزیز سایت همیارپروژه دعوت می کنم که برای انجام پروژه متلب خود آموزش های ما را دنبال نمایید.
نویسنده: زهرا رستمی
جهت سفارش پروژه به لینک زیر مراجعه نمایید :
همچنین می توانید برای ارتباط سریعتر با شماره و آیدی تلگرام زیر تماس حاصل کنید :
۰۹۱۲۹۵۴۰۱۲۲ – آیدی تلگرام : @fnalk
از طریق کلیک برروی آیکن های زیر میتوانید پروژه خود را در تلگرام و یا واتساپ برای ما ارسال کنید:

دیدگاهتان را بنویسید