







روند مینیمم سازی در نرم افزار مطلبدوشنبه 14, دسامبر 2020

روند مینیمم سازی در نرم افزار متلب
در ادامه آموزش های سایت همیارپروژه برنامه نویسی متلب ارائه خواهد شد .آموزشها از مقدماتی تا پیشرفته ادامه دارد و ما به شما کدنویسی در نرم افزار متلب را رایگان یاد خواهیم داد. با ما همراه باشید.

روند مینیمم سازی: الگوریتم کلی
.روند بازگشتی: تخمین جدید از روی تخمین فعلی قابل مقایسه است
![]()
.(k)x تخمین فعلی نقطه مینیمم تابع f، (K)a نرخ یادگیری و ( k )p بردار جستوجو است.
.در روشهای مختلف مینیمم سازی، بردار جستوجو متفاوت است.
.(K)p به گونهای تعیین میشود که مقدار تابع f در هر مرحله کاهش یابد.
.بردار جستوجو از روی بردار گرادیان و هسیان تابع محاسبه میشود.
دیدیم که اگر مسیر (k)p در جهت گرادیان باشد، مقدار مشتق جهتی کمترین میزان ممکن را خواهد داشت.
. در اینجا نیز با توجه به بست تیلور تابع f حول ) k ( x به سادگی دیده میشود که اگر بردار جستوجو در خلاف جهت گرادیان انتخاب شود.
بیشترین تنزل در مقدار تابع f را خواهیم داشت.
.الگوریتم بیشترین نزولبرابر است با:
![]()
.روش تعیین نرخ یادگیری (k)a :
_در نظر گرفتن یک مقدار ثابت. مثلا ۵٫,. یا
_یافتن (k)a در هر مرحله به گونهای که تابع ((۱+k)x)F نسبت به (k)a حداقل شود.
نرخ یادگیری بهینه
نکات مربوط به الگوریتم sd در متلب
.ثابت کنید نرخ یادگیری بهینه در الگوریتم SD برای توابع درجه دوم عبارت است از:
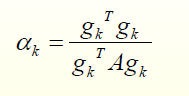
.مراحل متوالی الگوریتم SD برهم عمودند.
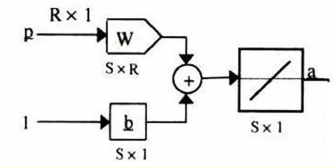
شبکه آدلاین در متلب
.شبکه آدلاین با با قانون یادگیری ویدرو-هوف (معروف به قانونlms) در سال ۱۹۶۰ و بعد از شبکه پرسپترون است.
ولی با تابع خطی ( به جای آستانه دو مقدار )
![]()
معدلات ویدرو-هوف در حالت تک نرون
.بازنویسی معادله خروجی فرمول بندی جدید
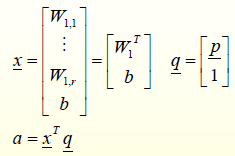
.تابع هزینه میانگین مربع
![]()
.تعیین نقطه ایستا از روی گرادیان تابع
توجه
.اگر بتوانیم معکوس ماتریس را محاسبه کنیم نیازی به الگوریتمهای مینیمم سازی نداریم.
.اگر نخواهیم ( یا نتوانیم ) معکوس R را محاسبه کنیم، الگوریتم مینیمم سازی SD را میتوان به کار برد.
_ در این حالت نیاز به محاسبه گرادیان تابع داریم.
. در حالت کلی مطلوب یا مناسب نیست که بردار d و ماتریس R محاسبه شوند. لذا تقریبی از الگوریتم SD یا همان LMS استفاده میشود.
_ استفاده از گرادیان لحظهای به جای گرادیان واقعی
الگوریتم LMS در متلب
.در واقع استفاده از خطای لحظهای به عنوان شاخص عملکرد
![]()
. دقت شود که![]()
. به کمک قاعده زنجیرهای به سادگی دیده میشود که
![]()
.قانون lms در حالت تک نرون:
![]()
. قانون lms در حالت کلی :
![]()
فرم دستهای یادگیری lms در حالت تک نرون
.شاخص اجرای در حالت تک نرون در متلب
_ n تعداد داده های یادگیری
![]()
.شاخص اجرای در حالت کلی s نرون
![]()
. در حالت تک نرون به سادگی دیده میشود:
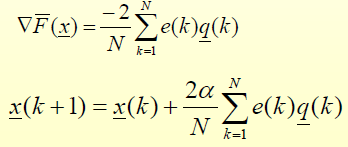
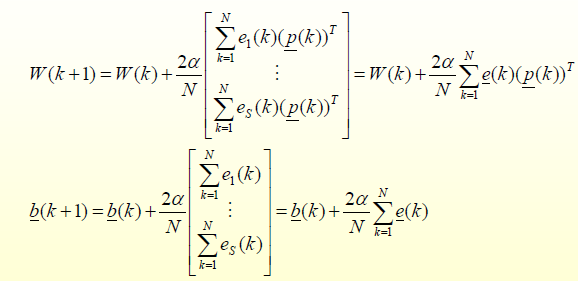
بهبودهایی بر LMS
. نرخ یادگیری متغیر با زمان
. استفاده از مومنتوم
کاربرد شبکه آدلاین در فیلترهای تطبیقی
. کاربردهای علمی فراوان در پردازش سیگنال دیجیتال
. استفاده از بلوک (Tapped Delay line)TDL در ورودی شبکه
. حذف تطبیقی نویز
شبکه های عصبی چند لایه پیشخور و یادگیری پس از انتشار خطا
.در شبکهههای MLP
_هر نرون دارای تابع غیر خطی است.
. یادگیری پس از انتشار خطا (BP):
_برای آمزش شبکههای عصبی چندلایه پرسپترون (MLP)
_ برای آموزش شبکههای عصبی چندلایه پرسپتررون (MLP)
_ تعمیمی از الگوریتم LMP ، لذا تقریبی از SD و در چارچوب یادگیری عملکردی است.
_ مبتنی بر قانون یادگیری اصلاح خطا
.اختلاف LMP و BP
_نحوه محاسبه و استفاده از مشتقات
_ بر خلاف آدلاین، بردار خطا تابعی غیر خطی از پارامترهای شبکه بوده و مشتقاتش به سادگی قابل محاسبه نیست.
در اینجا آشنایی با محیط متلب بخش صد و سوم به پایان رسیده است و در آموزش های بعدی به مباحث دیگر آموزش متلب می پردازیم. همچنین از شما مخاطبین عزیز سایت همیارپروژه دعوت می کنم که برای انجام پروژه متلب خود آموزش های ما را دنبال نمایید.
نویسنده: زهرا رستمی
جهت سفارش پروژه به لینک زیر مراجعه نمایید :
همچنین می توانید برای ارتباط سریعتر با شماره و آیدی تلگرام زیر تماس حاصل کنید :
۰۹۱۲۹۵۴۰۱۲۲ – آیدی تلگرام : @fnalk
از طریق کلیک برروی آیکن های زیر میتوانید پروژه خود را در تلگرام و یا واتساپ برای ما ارسال کنید:

دیدگاهتان را بنویسید